히스토그램(Histogram)이란?
칼럼의 데이터 분포를 시각적으로 나타내는 통계 정보로 MySQL 8.0 버전부터 사용 가능하다.
- 데이터의 빈도를 그룹화하여 각 그룹의 빈도를 막대그래프로 표시한다.
- 데이터의 분포를 빠르게 이해하고 이상치를 감지하는 데 도움이 되며, MySQL의 옵티마이저가 쿼리 실행 계획을 수립할 때 활용된다.
히스토그램 정보 수집 과정
1. 다음 명령을 실행하여 히스토그램 정보를 수동으로 수집 및 관리 (자동 수집 X)
ANALYZE TABLE 테이블명 UPDATE HISTOGRAM ON 칼럼명;2. 수집된 히스토그램 정보를 시스템 딕셔너리에 저장
3. MySQL 서버가 시작될 때 딕셔너리의 히스토그램 정보를 `information_schema` 데이터베이스의 `column_statistics` 테이블로 로드
4. `column_statistics` 테이블을 SELECT하여 히스토그램 정보를 조회
SELECT * FROM INFORMATION_SCHEMA.COLUMN_STATISTICS;히스토그램 삭제 및 미사용
- 히스토그램의 삭제 작업은 테이블의 데이터를 참조하는 것이 아니라 딕셔너리 내용만 삭제하기 때문에 다른 쿼리 처리의 성능에 영향을 주지 않고 즉시 완료된다. 하지만 히스토그램이 사라지면 쿼리의 실행 계획이 달라질 수 있으므로 주의!
ANALYZE TABLE ... DROP HISTOGRAM- 만약 히스토그램을 삭제하지 않고 MySQL 옵티마이저가 히스토그램을 사용하지 않도록 하고 싶다면?
- 다음과 같이 `optimizer_switch` 시스템 변수의 값을 글로벌로 변경하면 된다!
- 이제 MySQL 서버의 모든 쿼리가 히스토그램을 사용하지 않는다.
SET GLOBAL optimizer_switch='condition_fanout_filter=off';
히스토그램의 타입
MySQL 8.0 버전에서는 2종류의 히스토그램 타입(`싱글톤(singleton) 히스토그램`과 `높이 균형(Equi-Height) 히스토그램 `)이 지원된다.
- 히스토그램은 `버킷(Bucket)` 단위로 구분되어 레코드 건수나 칼럼값의 범위가 관리된다.
- 히스토그램의 모든 레코드 건수 비율은 누적으로 표시된다.
싱글톤(Singleton) 히스토그램
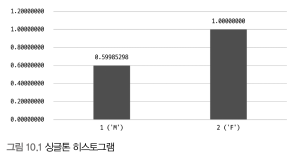
- 칼럼값 개별로 레코드 건수를 관리하는 히스토그램 ➡️ 칼럼값 별로 버킷이 할당됨
- `Value-Based 히스토그램` 또는 `도수 분포`라고도 불림
- 각 버킷이 `칼럼의 값`과 `발생 빈도`의 2개 값을 가짐
- 주로 코드 값과 같이 유니크한 값의 개수가 상대적으로 적은(히스토그램 버킷 수보다 적은) 경우 사용된다.
높이 균형(Equi-Height) 히스토그램
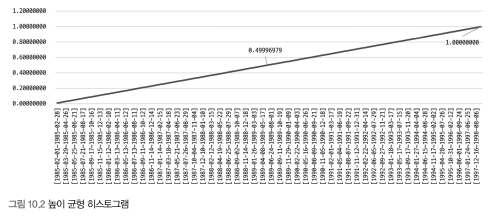
- 칼럼값의 범위를 균등한 개수로 구분해서 관리하는 히스토그램 ➡️ 개수가 균등한 칼럼값의 범위별로 하나의 버킷이 할당됨
- `Height-Balanced 히스토그램`이라고도 불림
- 각 버킷이 `범위 시작 값`과 `범위 마지막 값`, `발생 빈도율`, `각 버킷에 포함된 유니크한 값의 개수` 등 4개의 값을 가짐
`Histogram` 객체
{
"buckets": [
[
1,
0.3333333333333333
],
[
2,
0.6666666666666666
],
[
3,
1
]
],
"null-values": 0,
"last-updated": "2017-03-24 13:32:40.000000",
"sampling-rate": 1,
"histogram-type": "singleton",
"number-of-buckets-specified": 128,
"data-type": "int",
"collation-id": 8
}buckets
- 히스토그램 버킷 정보. 버킷 구조는 히스토그램 유형(`histogram-type`)에 따라 다르다.
- `singleton` - `[버킷의 값, 값의 누적 빈도 (double)]`
- `equi-height` - `[버킷의 하한값, 버킷의 상한값, 값의 누적 빈도 (double) , 범위 내에 있는 고유 값의 수]`
null-values
- 히스토그램에 포함된 NULL 값의 수 (0.0 ~ 1.0)
- `0`이면 열에 NULL 값이 없음을 의미함
last-updated
- 히스토그램이 생성된 시간
sampling-rate
- 히스토그램을 만들기 위해 사용된 샘플링된 데이터의 비율 (0.0 ~ 1.0)
- `1`이면 전체 데이터가 읽혔음을 의미함
histogram-type
- 히스토그램 유형
- `singleton`: 하나의 버킷이 하나의 단일 값을 나타냄
- `equi-height`: 하나의 버킷은 값의 범위를 나타냄
numbers-of-buckets-specified
- 히스토그램을 생성할 때 설정했던 버킷의 개수
- 따로 지정하지 않았다면 기본으로 버킷이 사용됨 (최대 128까지 설정 가능)
data-type
- 히스토그램의 데이터 타입
collation-id
- 문자열 데이터의 정렬 순서를 식별하는 데 사용되는 collation ID
💡
특정 열의 고유한 값의 수 > 버킷 수(`numbers-of-buckets-specified`) ➡️ `높이 균형 히스토그램`
특정 열의 고유한 값의 수 ≤ 버킷 수(`numbers-of-buckets-specified`) ➡️ `싱글톤`
예를 들어,
- `'M'`과 `'F'`라는 값만 갖는 `gender` 칼럼에 대한 히스토그램을 생성할 때, 버킷 개수를 지정하지 않았거나 2개 이상의 값으로 명시적으로 설정했다면 `싱글톤 히스토그램`으로 생성된다.
- `1`부터 `100`까지의 값을 갖는 `age` 칼럼에 대한 히스토그램을 생성할 때, 버킷 개수를 100개(`age` 칼럼 고유한 데이터 개수)보다 작게 설정했다면 `높이 균형 히스토그램`으로 생성된다.
히스토그램의 용도
히스토그램의 특징
- 히스토그램은 데이터 분포를 시각화하여 제공한다.
- 데이터의 형태와 특성을 한눈에 파악하기 쉽다 ➡️ 평균/분산 등을 파악하기 쉽고, 이상치의 존재를 확인할 수 있다
- 옵티마이저가 효율적인 실행 계획을 수립하는데 도움을 준다. ➡️ 상황에 따라 적절한 드라이빙 테이블을 선택하여 조인 횟수를 줄일 수 있다.
- 히스토그램은 요청 시에만 생성되거나 갱신되므로 테이블 데이터가 수정될 때 오버헤드가 발생하지 않는다.
- 히스토그램 정보 갱신 주기가 너무 길어지면 데이터 분포 변화를 적절히 반영하지 못한다는 문제점이 있다. ➡️ 유연성 감소
그래서 히스토그램을 어떤 상황에서 사용해야 할까?
MySQL 8.0 버전에서 히스토그램은 주로 인덱싱되지 않은 칼럼에 대한 데이터 분포도를 참조하는 용도로 사용된다.
- 인덱스된 칼럼을 검색 조건으로 사용하는 경우, 히스토그램을 사용하지 않고 `인덱스 다이브(Index Dive)`를 통해 직접 수집한 정보를 활용하기 때문이다!
- `인덱스 다이브`: MySQL 서버에서 최적의 실행 계획을 찾기 위해 실제 인덱스의 B-Tree를 샘플링하여 확인하는 과정
- 실제 검색 조건의 대상 값에 대한 샘플링을 실행하는 것이므로 항상 히스토그램보다 정확한 결과
추가적으로,
- 히스토그램은 데이터 분포를 제공함 ➡️ 조인 또는 필터링 조건에서 사용되는 칼럼의 경우
- 히스토그램은 요청 시에만 생성되거나 갱신됨 ➡️ 데이터 변경이 자주 발생하지 않는 데이터의 경우
등의 상황에서 옵티마이저가 최적의 실행 계획을 수립하는데 도움이 된다고 볼 수 있다.
Ref
Real MySQL 8.0 - 10장 실행 계획
https://dev.mysql.com/blog-archive/histogram-statistics-in-mysql/
https://hoing.io/archives/1051
https://dev.mysql.com/doc/refman/8.0/en/optimizer-statistics.html
https://ssseung.tistory.com/196
https://medium.com/daangn/index-dive-%EB%B9%84%EC%9A%A9-%EC%B5%9C%EC%A0%81%ED%99%94-1a50478f7df8
'Backend > Database' 카테고리의 다른 글
| [MySQL] 문자열 패턴 매칭 연산자 (REGEXP, LIKE) (2) | 2024.02.22 |
|---|---|
| [MySQL] 실행 계획 - partitions 칼럼 (0) | 2024.02.15 |
| [MySQL] Read Ahead에 대해서 알아보자 (0) | 2024.01.25 |
| [MySQL] B-Tree 알고리즘 (0) | 2024.01.18 |
| [MySQL] 암호화 알고리즘 (0) | 2024.01.11 |
