사용자 수의 증가로 인해 발생하는 트래픽을 안정적으로 처리하기 위해서, 데이터 손실을 방지하기 위해서 등 서비스 운영에 있어 데이터베이스 확장은 중요한 요소라고 할 수 있다. 오늘은 데이터베이스 확장 방식인 클러스터링, 복제에 대해서 간단히 알아보고 어떤 상황에 적합한지 정리해보고자 한다.
데이터베이스 구성 방식
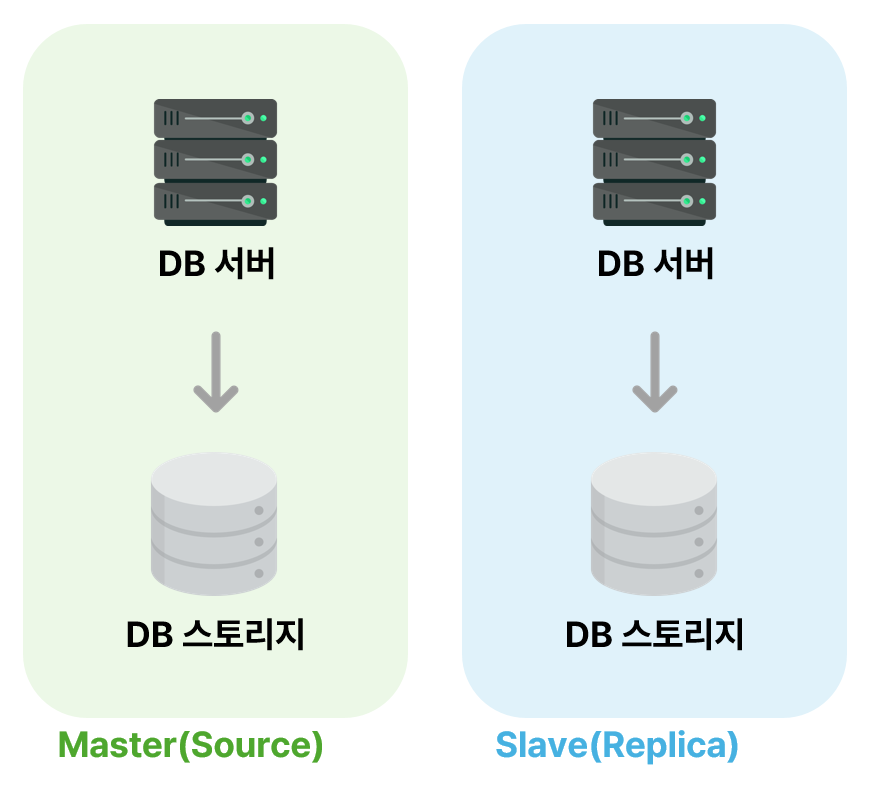
가장 기본적인 데이터베이스 구성은 다음과 같이 `DB 서버`와 디스크 역할을 하는 `DB 스토리지`가 1:1이 되도록 구성하는 것이다.
이러한 구조로는 트래픽의 증가로 성능이 저하되거나, 데이터베이스 서버 다운으로 인한 서비스 중단 등의 문제를 해결할 수 없다.
`클러스터링`, `복제` 기법을 활용하여 데이터베이스를 확장하여 이러한 문제를 해결할 수 있다.
클러스터링(Clustering)
여러 대의 DB 서버를 하나의 시스템으로 묶어서 단일 시스템처럼 동작하게 만드는 기술
고가용성: `SPOF`와 같은 문제를 해결하여 가용성이 향상됨
부하 분산: 다수의 서버 운영으로 하나의 서버에 가해지는 부하가 감소됨 ➡️ CPU, 메모리 관리 차원에서 이득
확장성: 필요에 따라 새로운 서버를 추가하여 더 많은 요청을 처리할 수 있음
스토리지 공유: 각 서버는 일반적으로 동일한 데이터를 공유하는 하나의 공통 스토리지에 접근함
이로 인해 병목 현상이 발생할 수 있음
동기 방식: 동기 방식으로 노드들 간의 데이터를 동기화함 ➡️ 데이터 일관성을 확보할 수 있지만 동기화하는 시간이 필요함
💡 SPOF(Single Point of Failure, 단일 장애 지점)
어떤 특정 지점에서의 장애가 전체 시스템의 동작을 중단시켜버릴 수 있는 경우, 해당 지점을 단일 장애 지점이라고 부름
복제(Replication)
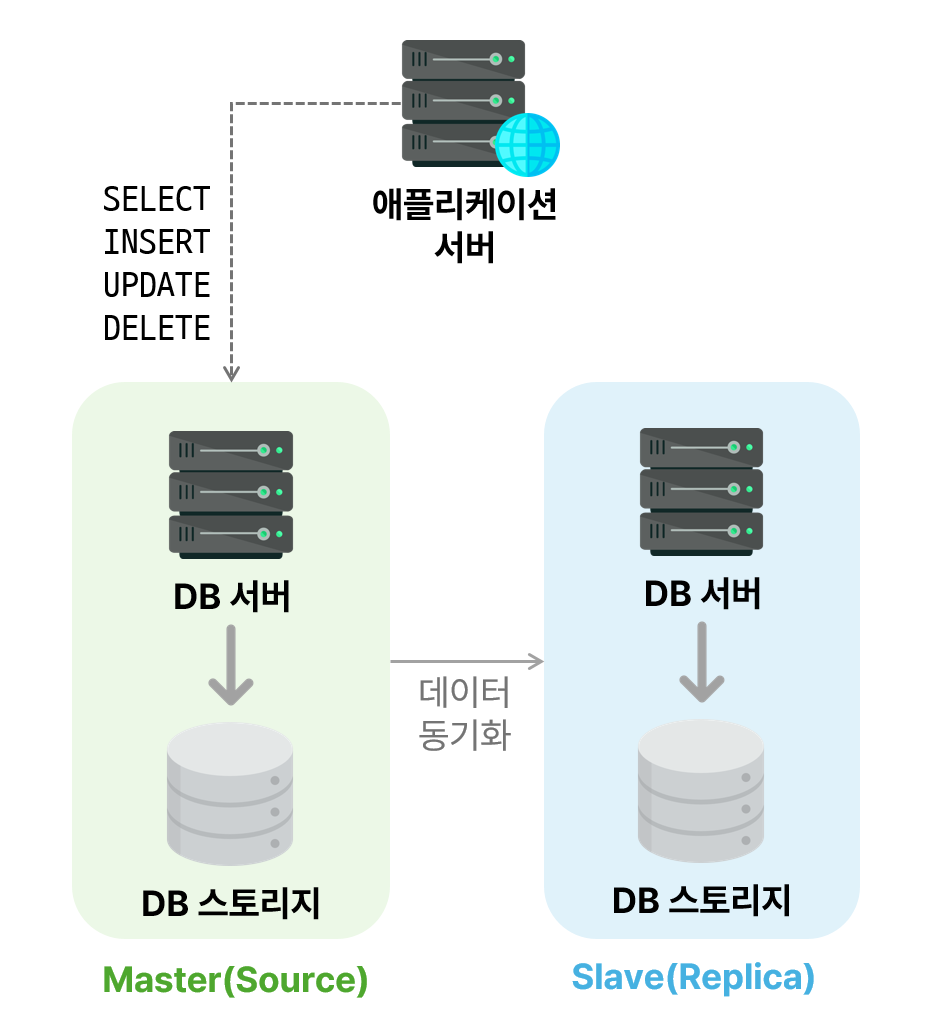
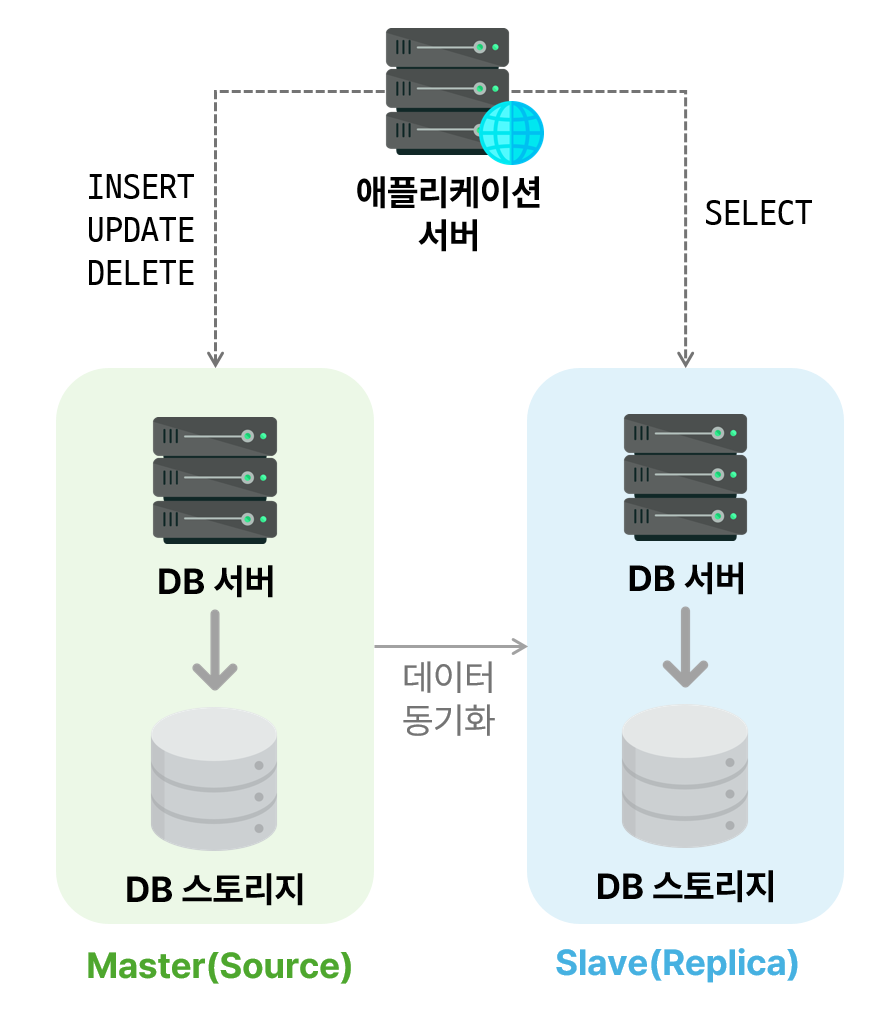
DB 스토리지까지 복제하는 방식으로, 여러 개의 DB를 `Master-Slave` 구조로 구축함
스케일 아웃: DB 서버를 스케일 아웃하여 성능 향상 가능
데이터 백업: 슬레이브는 마스터의 복제본이므로 데이터 손실이 발생했을 때 복제본을 사용하여 복구 가능
데이터의 지리적 분산: 소스 서버와의 물리적인 거리가 있을 경우, 레플리카 서버를 구축하여 응답 속도 개선 가능
비동기 방식: 비동기 방식으로 데이터를 동기화함 ➡️ 지연 시간이 거의 없지만 데이터 일관성을 보장되지 않음
백업용
Master 서버에서 발생한 데이터 변경 사항을 Slave 서버로 복제함
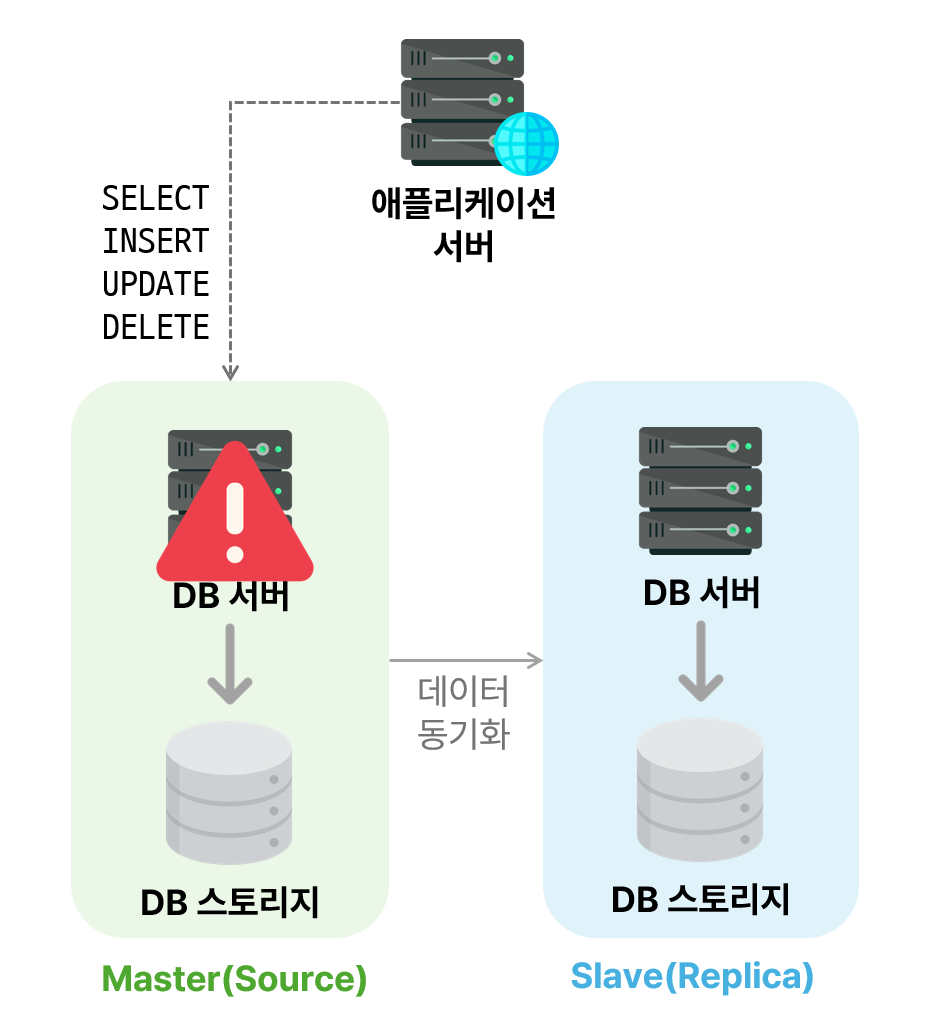
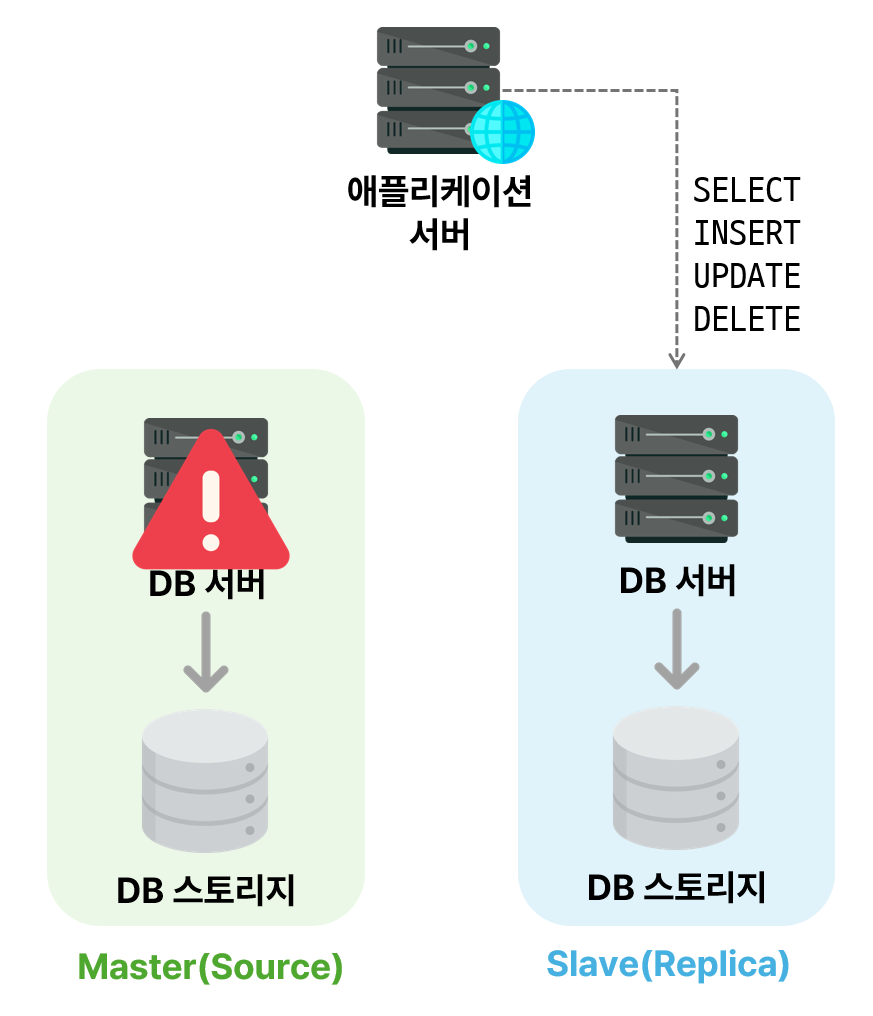
소스 서버에서 문제가 발생했을 때, 일시적으로 레플리카 서버로 `Failover`해서 서비스를 중단 없이 제공할 수 있음
`Failover`: 시스템 장애 시 준비되어 있는 다른 시스템으로 대체되어 운영되는 것
부하 분산용
Master 서버의 부하를 줄이기 위해 Slave 서버를 읽기 전용으로 사용함
읽기 작업이 많은 경우 위와 같이 구성하여 성능을 향상시킬 수 있음
하지만 복제 서버에 문제가 발생했을 경우 전체 서비스 장애로 이어지게 되므로 복제 서버가 하나인 경우에는 예비용으로만 사용하는 것이 적합함 ➡️ 멀티 레플리카 구성으로 사용하면 됨
정리
클러스터링
여러 대의 DB 서버를 구축하여 하나의 스토리지를 공유하는 방식
읽기 및 쓰기 작업을 모두 분산시킬 수 있으므로 높은 성능을 제공할 수 있음
Failover 시스템 구축을 위해 사용함
복제
한 서버에서 다른 서버로 데이터가 동기화되는 방식
읽기 작업이 많을 때 성능 향상 효과를 얻을 수 있음
지리적으로 분산시킬 때도 적합함
📌 클러스터링 ➡️ 가용성, 확장성 복제 ➡️ 안정성, 읽기 성능
읽기 작업이 많은 경우 복제를 이용하여 읽기 작업과 쓰기 작업을 분리하여 처리하는 것만으로 성능 개선 효과를 얻을 수 있다.
이처럼 읽기 작업이 많거나 데이터 안정성이 중요할 때, 지리적 이점을 얻고 싶을 때는 복제가 적절하다.
하지만 서비스 규모가 크고 트래픽이 많이 발생할 경우, 동일한 작업을 분산시켜서 병렬로 처리할 수 있는 클러스터링이 더 적합하다.